Data Discovery
Data discovery er en proces, der involverer at identificere, kategorisere og forstå data, som en organisation besidder.
Med data discovery kan organisationer hurtigt finde og beskytte følsomme oplysninger. Dette er især vigtigt for at efterleve regler som GDPR, der pålægger organisationer at beskytte personoplysninger. Når man ved, hvor data befinder sig, kan man lettere indføre sikkerhedsforanstaltninger som adgangskontrol, kryptering og løsninger til at forebygge datatab (DLP). Samtidig bidrager data discovery til at lave bedre risikovurderinger og til at forstå konsekvenserne af et potentielt databrud.
Hvis man ikke ved, hvilke data man har, kan man heller ikke beskytte dem ordentligt, hvilket udgør en stor sikkerhedsrisiko, og derfor er data discovery en vigtig del af en effektiv IT-sikkerhedsstrategi og risikostyring for enhver organisation, uanset størrelse.
Implementering af Data Discovery
Identifikation af data og kilder
Det første skridt i en data discovery-proces er at skabe et overblik over, hvor organisationens data opbevares, og hvordan det bruges. Dette inkluderer både struktureret data, som findes i databaser og regneark, og ustruktureret data, der gemmes i filer, e-mails, cloud-tjenester eller endda på medarbejderes enheder.
Processen kræver en detaljeret gennemgang af hele organisationens IT-miljø og kan udføres ved hjælp af både manuelle metoder og automatiserede værktøjer.
Interviews med medarbejdere kan også være en værdifuld metode til at opdage skjulte datasæt, der måske ikke fremgår af dokumentationen. En grundig data discovery kan afsløre oversete eller uventede data, som tidligere ikke blev betragtet som vigtige, men som kan have stor betydning for sikkerhed og compliance.
Det er også denne viden, du skal benytte når det kommer til compliancekrav til fx GDPR artikel 30 om at lave en fortegnelse.
Klassificering af data
Når datakilderne er fundet, skal de klassificeres efter deres følsomhed. Dette indebærer at identificere data, der er omfattet af lovgivning, som eksempelvis personoplysninger, eller som er kritiske for virksomhedens drift. Klassificeringen hjælper med at fastlægge hvilke sikkerhedsforanstaltninger der skal indføres for hver type data og sikrer, at de mest følsomme oplysninger får ekstra beskyttelse.
Data discovery og metadata
En vigtig del af data discovery er at forstå dataens bevægelser og relationer. Dette opnås gennem analyse af metadata, som giver indsigt i dataens oprindelse, ejerskab, opdateringshistorik og anvendelse. Ved at forstå, hvordan data bevæger sig gennem jeres systemer, kan I lettere finde og lukke sikkerhedshuller. Når datasammenhænge er visualiseret, kan organisationen bedre forstå, hvordan data bruges, og hvor det er sårbart over for potentielle angreb eller misbrug.
Variationer i metoder til data discovery
Der er forskellige metoder til at udføre data discovery, som varierer alt efter organisationens størrelse og behov. Små organisationer kan ofte klare sig med manuelle analyser, hvor IT-afdelingen gennemgår data manuelt for at få et overblik.
Større og mere komplekse organisationer har typisk brug for automatiserede værktøjer, der kan scanne store datamængder hurtigt og effektivt. Ofte kombineres automatisering med manuelle processer for at validere resultaterne og sikre, at data bliver forstået i konteksten af virksomhedens aktiviteter.
Tekniske og praktiske aspekter
For at få succes med data discovery kræves både teknisk og forretningsmæssig forståelse. IT-specialister spiller en vigtig rolle i at konfigurere og analysere systemerne, mens forretningsansvarlige bidrager med indsigt i dataens værdi og anvendelse. Moderne compliance-software gør processen enklere ved at automatisere scanningen af data og generere rapporter, som både IT og forretningsansvarlige kan bruge til at træffe informerede beslutninger.
Løbende proces
Det er vigtigt at forstå, at data discovery ikke er en engangsopgave. Data flytter sig og ændrer sig konstant i takt med, at nye oplysninger oprettes, deles og slettes. Derfor er regelmæssige opdateringer og audits en nødvendig del af processen for at sikre, at organisationen til enhver tid har styr på sine data og kan reagere hurtigt på nye risici.
Trusselsscenarier
Data discovery hjælper med at mindske risikoen for flere forskellige trusler.
|
Trusselsscenarie
|
Foranstaltning
|
|
Databrud
|
Data discovery finder og markerer følsomme data samt deres placering, hvilket gør det muligt at fokusere sikkerhedsindsatsen der, hvor behovet er størst.
|
|
Uautoriseret adgang
|
Skaber overblik over data og adgangsrettigheder, så sikkerhedshuller kan identificeres og lukkes hurtigt.
|
|
Data tab
|
Hjælper med at finde kritiske data, så organisationen kan prioritere backup og beredskabsplaner.
|
|
Manglende overholdelse af regler
|
Identificerer data, der er underlagt lovgivning som GDPR, og sikrer, at compliancekrav overholdes.
|
|
Utilsigtet datadeling
|
Giver indsigt i datastrømme og identificerer områder, hvor uautoriseret deling kan forekomme, så det kan forhindres.
|
|
Interne trusler
|
Gør det muligt at identificere brugere med særlige privilegier og deres adgang til data, så potentielle risici kan begrænses.
|
|
Ransomware
|
Hjælper med at finde kritiske data, så disse kan prioriteres i genopretningen efter et angreb.
|
Risiko reduktion
Ved at identificere og klassificere sine data kan organisationer lave bedre risikovurderinger og derigennem proaktivt indføre målrettede sikkerhedsforanstaltninger, der hvor de har størst effekt, hvilket bidrager til en effektiv reduktion af risikoen for databrud.
Hvis I har identificeret risikoen for utilsigtet datadeling i jeres risikovurdering, kan data discovery hjælpe jer med at lokalisere de filer, der indeholder følsomme oplysninger, og sikre, at der er kontrol med, hvordan de deles.
Informationsaktiver og processer
Data discovery kan anvendes til at kortlægge data på flere typer informationsaktiver fx servere, databaser, cloud-lagring, lokale filer, e-mails, IoT-enheder og mere.
Forretningsprocesser som kundehåndtering, bogføring, produktion, forskning og udvikling er stærkt afhængige af data, hvor data discovery kan understøtte at data behandles korrekt.
Implementering
Omkostninger ved implementering
At implementere data discovery kræver både tid og ressourcer. Omkostningerne varierer afhængigt af organisationens størrelse, kompleksitet og de værktøjer og metoder, der vælges.
For at udføre data discovery skal der sammensættes et team, der kombinerer teknisk ekspertise med forretningsforståelse. Specialiseret software og eventuelt eksterne konsulenter kan også være nødvendige.
Praktiske trin i implementeringen
Start med at udarbejde en klar plan, der definerer scope og identificerer relevante værktøjer. Involver interessenter fra alle relevante afdelinger.
Selve implementeringen kan omfatte både automatiserede scanninger af data og manuel gennemgang af resultater for at sikre nøjagtighed og forståelse.
Databehandling er i konstant bevægelse hvor nye data opstår og slettes løbende, og derfor kræver det regelmæssige opdateringer og audits af sin data discovery process.
Automatisering vs. manuelle processer
Automatisering er en nøglefaktor i effektiv data discovery, især i større organisationer med store datamængder.
Moderne værktøjer kan hurtigt scanne og identificere følsomme oplysninger, hvilket sparer tid og reducerer fejl. Samtidig kan manuel validering være nødvendig for at sikre, at resultaterne bliver forstået i konteksten af organisationens aktiviteter.
Mindre organisationer med færre datakilder kan eventuelt klare sig med manuelle metoder, men for de fleste virksomheder er automatiserede værktøjer afgørende for en skalerbar og effektiv data discovery-proces.
Udfordringer
Selvom data discovery er en vigtig proces, kan der opstå udfordringer under implementeringen. Her er nogle af de mest almindelige udfordringer og deres løsninger.
|
Udfordring
|
Løsning
|
|
Data spredt over forskellige systemer
|
Automatiserede scanningsværktøjer kan integrere data fra mange forskellige kilder og skabe et samlet overblik.
|
|
Manglende data kvalitet
|
Implementér processer, der forbedrer datakvaliteten, som fx validering og standardisering af data
|
|
Kompleksitet af data
|
Brug specialiserede konsulenter eller værktøjer, der er designet til at håndtere komplekse datastrukturer.
|
|
Modstand fra medarbejdere
|
Uddan medarbejdere om vigtigheden af data discovery, samt hvordan det gavner organisationen.
|
|
Ressourcemangel
|
Prioritering af de mest kritiske data og implementering af data discovery i faser
|
Data Discovery Software
Når det kommer til data discovery, spiller softwareløsninger en central rolle i at identificere, klassificere og analysere data effektivt. Der findes mange udbydere på markedet, som tilbyder værktøjer designet til både små og store organisationer. Valget af den rette software afhænger ofte af virksomhedens behov, datakompleksitet og budget.
Microsoft Purview er en løsning til data governance og compliance, som også inkluderer data discovery-funktioner. Den er særlig velegnet til virksomheder, der allerede bruger Microsofts økosystem, da den integrerer problemfrit med Azure, Microsoft 365 og andre Microsoft-tjenester.
Varonis er en anden udbyder af data discovery og data governance-løsninger. Softwaren fokuserer på at kortlægge og beskytte følsomme data, især på tværs af ustrukturerede datakilder som filer, mapper og e-mails.
Relaterede foranstaltninger
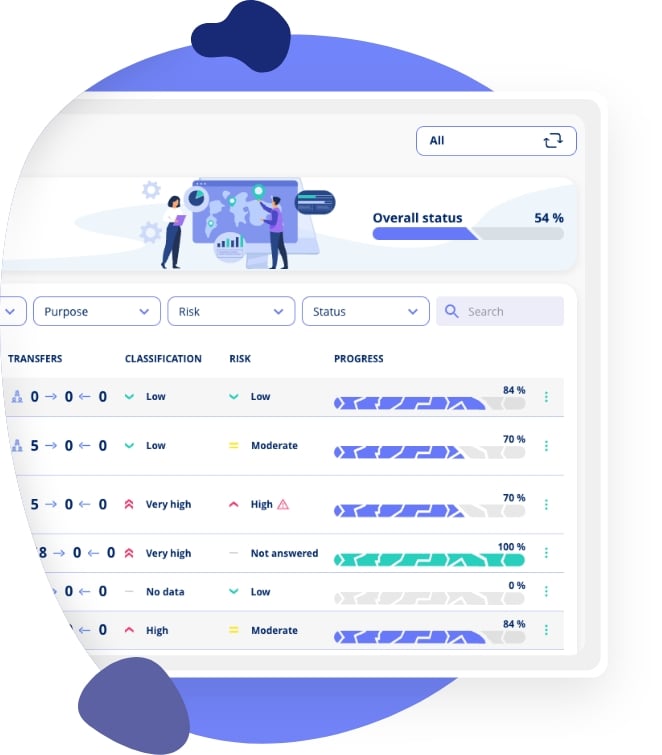
Data discovery kan bruges i sammenhæng med en række andre sikkerhedsforanstaltninger:
For at fungere effektivt bør data discovery være en del af organisationens overordnede IT-sikkerhedspolitik og styres af et ISMS.















































































.jpeg)
.jpg)
.jpg)



.jpg)

.png)


.jpeg)



.jpg)


.jpg)